HTML output for commands
As you probably know, TextMate derives a lot of power from the underlying shell infrastructure in OS X. A place where this is evident is in the bundle editor, which allow you to (amongst others) setup (shell) commands and scripts to run.
Other than export various shell variables to the command, TextMate give you control over what the command should receive as input (stdin) and what to do with the output (stdout). One output option is to show it as HTML, which allow for more than just pretty printing the result. I’ll give some examples of that in this post.
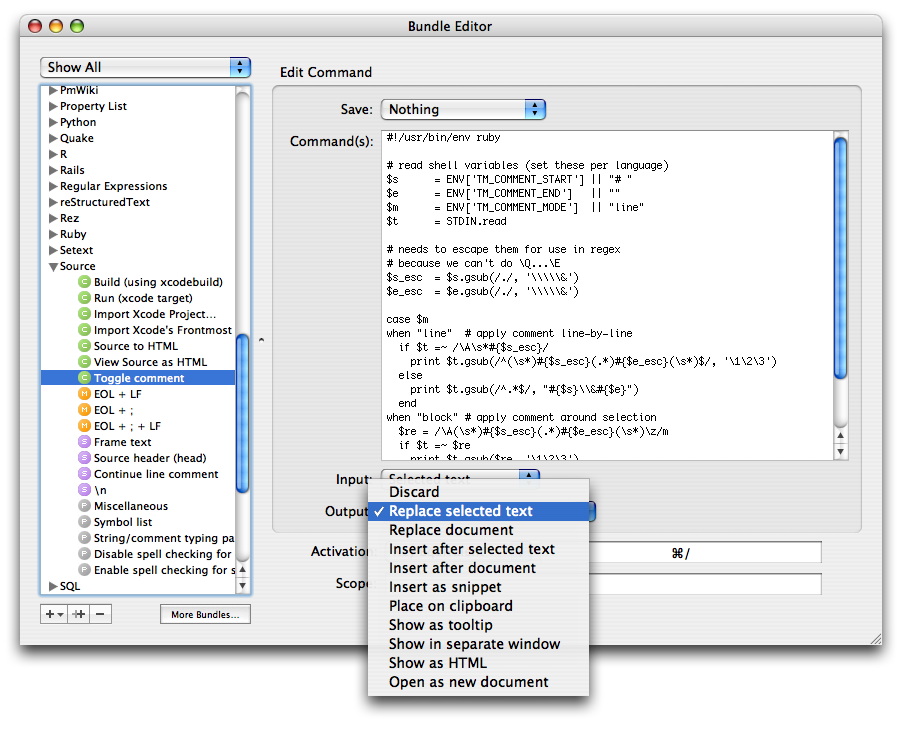
Pretty printing
I mentioned that the HTML output option allowed for more than pretty printing, but let us start by getting that out of the way.
Not surprisingly, by letting the command output HTML instead of plain text, the result can be significantly nicer, since we have a rather complete HTML/CSS renderer on our hand. Several standard and 3rd party shell commands already support outputting as HTML, e.g. man uses groff to typeset the manual page, which has an HTML output option (though Apple’s developer tools comes with rman which has nicer (HTML) output), the same goes for mysql (to do queries from the shell), xmllint and (a bit surprisingly) so is the case for a lot of other commands. You’ll have to check the manual for whatever command you’re using, to see if it support HTML output.
For scripts you write yourself, it should be straightforward to output HTML, since it’s just wrapping your output in tags, and optionally start by outputting a style sheet.
A nice property of the HTML output is that window size and position is stored for each different command. In addition you can also let the command change dimensions by using JavaScript.
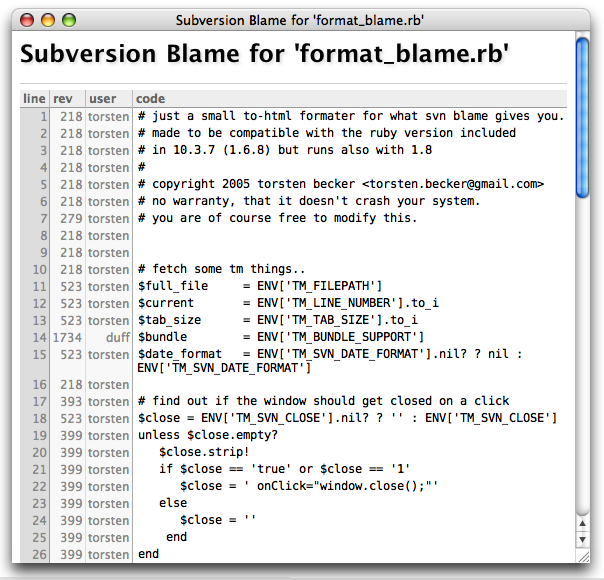
When you have commands with a lot of plain text output, there’s the option of piping this output through a script to parse and convert it to HTML. This is done for a lot of the subversion commands, below is a grab of svn blame "$TM_FILEPATH" piped through format_blame.rb.
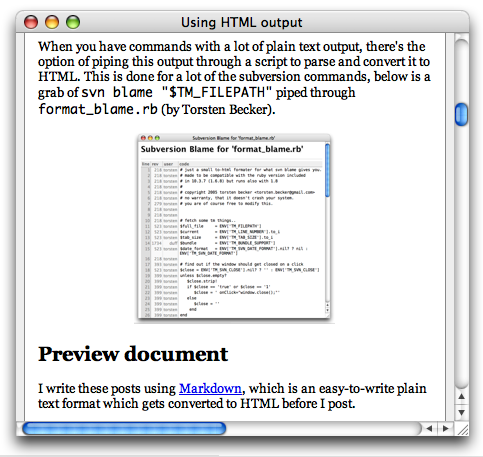
Preview document
I write these posts using Markdown, which is an easy-to-write plain text format which gets converted to HTML before I post.
It’s often useful to get a preview while working on the document, and by creating a command which runs Markdown.pl, has input set to entire document, and output set to be shown as HTML, we have that preview command. Actually the live HTML preview also supports an arbitrary shell command as a real-time filter, but generally I prefer to call up the preview and close it again, rather than use the “live” one. The command also makes it easy to include a style sheet in the output and set the base URL (so that images are correctly loaded with my setup).
There are other text-to-HTML conversion tools for which this of course also work, but in addition to being able to show HTML, the WebKit (used for the HTML output) can show PDF files (starting with Tiger, unless you have Schuberts PDF browser plugin).
So if we’re working with a markup language which is converted to PDF (like LaTeX) we can preview that from within TextMate. The way to do this requires slightly more work than the simple filter, but not much.
Since the HTML output will always treat the output from your command as text/html, we need to output HTML which redirects to the PDF file (rather than dump it to stdout). This can be done by printing a simple meta/refresh tag, but there’s one problem. Some months ago WebKit was updated so that it will not follow a link to the file://-scheme, if the source page is not from file://. To counter this, TextMate has a tm-file://-scheme which redirects to the file://-scheme, so we need to use that instead.
With that in place, we can now make a simple command like this:
if pdflatex -output-directory /tmp -interaction=nonstopmode /dev/stdin; then
echo '<meta http-equiv="refresh" content="0; tm-file:///tmp/stdin.pdf">'
fi
It runs pdflatex on stdin, which outputs a PDF file in /tmp that we redirect to (if pdflatex was successful).
Preview through apache
Above we saw how we could redirect the HTML output to another URL. It is in fact a mini browser (use ⌘← to go back, after following a link) which is useful in other situations as well.
For example if you edit files in your ~/Sites folder, and these files make use of PHP or similar that needs to be resolved by apache, you need to preview them through http:// rather than file://, and for this we can also make a general command.
To translate the file path into the equivalent http://-URL we use the $HOME variable to chop off the prefix of the path, and the $USER variable to figure out under which user the file is located, when accessed through http://. So the redirect command becomes:
echo "<meta http-equiv='Refresh' content='0;
URL=http://localhost/~$USER${TM_FILEPATH#$HOME/Sites}'>"
So if we’re working on /Users/duff/Sites/test/index.php, running the above command will redirect the HTML output to http://localhost/~duff/test/index.php and show that page.
Hyper-linking back to TextMate
So far we’ve dealt with read-only HTML output. Often though the output is intimately related to our current buffer or files in our project.
For example in the case of pdflatex, the command may output errors pointing to specific line numbers, svn blame has a 1:1 relationship with lines in the document, which makes linking logical, and even redirecting to apache when we’re testing PHP scripts, can output syntax errors that point back to our source document.
To allow this hyper-linking, TextMate offers a txmt://-scheme which currently support one command (open) which can have up to three arguments (url, line, and column). The URL needs to be a file://-URL, line and column indicate where the caret should be placed in the file. You can leave out the URL argument to have the link point to current buffer.
So to start with a simple example. If we have a convention of placing TODO comments in our file (to indicate that something needs to be done at that location) we can harvest all these TODO markings from current file by running a command with input set to entire document:
grep -wn TODO
Here the -n argument makes grep output the line number on which the match was found. Using perl to do a regexp replace on each line to turn it into a link with the line number from grep, we end with:
grep -wn TODO|perl -pe \
's|(\d+):(.*)|<a href="txmt://open?line=$1">$2</a><br>|'
A better version of this would combine find and grep to find TODO markings in all files in the project folder, and link to these (adding the URL argument to the txmt://-link). Such command can be found in the TODO bundle.
Process substitution
It’s often useful to do something like the above when running a build process. E.g. to run g++ on the current file, and catch errors, we can do:
g++ "$TM_FILENAME" -o "${TM_FILENAME%.*}"|perl -pe \
's|^.*?:(\d+):\s*(.*?)$|<a href="txmt://open?line=$1">$2</a>|'
But since it’s likely that we want to take further action if the build succeeds (or fails), we’d need to put an if in front of the command. But when using pipes, the return code of the expression is that of the last command in the pipe chain. So something like this will output succeed!, even though the first command “fails”:
if false|true; then
echo succeed!
fi
Luckily bash has a neat feature that we can use in this situation. The feature is called process substitution and works by using >(«cmd»), this will run «cmd» with its input set to a named pipe, and replace the entire expression with that name. Normally this is useful when a program insists on taking a filename as argument for the result to be written to, instead of writing the result to stdout.
For example scp (secure copy) copies a file from one location to another. Let’s pretend that scp is the only way we can reach file on server, and we want to perform a word count (wc) on file, but w/o first making a local copy. In this case we can execute:
scp server:file >(wc)
Here scp will write the remote file to the named pipe, and wc will read from that same pipe.
Process substitution goes both ways, we can for example also do the following:
diff -u file <(pbpaste)|mate
What this does is make diff compare file with what’s on the clipboard (using pbpaste to dump it to a named pipe that diff reads from). The output is piped into TextMate, where you’ll get to see the result with nice syntax coloring.
Back to hyper-linking
Process substitution can be used by letting the perl replacement script run as its own process, and have the output from gcc redirected to this process, instead of using normal piping (actually it’s stderr we want to redirect). It looks like this:
g++ "$TM_FILENAME" -o "${TM_FILENAME%.*}" \
2> >(perl -pe 's|^.*?:(\d+):\s*(.*?)$|<a href="txmt://open?line=$1">$2</a>|')
Now we can test the result of g++ with a simple if, so we can extend it to:
echo -n "<title>Compile results for $TM_FILENAME</title><pre>"
if g++ "$TM_FILENAME" -o "${TM_FILENAME%.*}" \
2> >(perl -pe 's|^.*?:(\d+):\s*(.*?)$|<a href="txmt://open?line=$1">$2</a>|')
then echo "</pre><h3>Build succeded</h3>"
else echo "</pre><h3>Build failed</h3>"
fi
It will output whether or not the build succeeded, after gcc has run, and in case of errors, these will be clickable.
For Xcode projects there’s already a command to parse the output from xcodebuild with nice output and clickable links located in the Source bundle.
Redirect to web service
Above we gave examples where we ran a shell command on our document, and “parsed” the result. Since we have the ability to show HTML, why not use a web service with our document?
One web service that you may know is W3C’s HTML validator. It’s not a service as in XML-RPC, SOAP or similar (although I didn’t check if such interface exists), but that only makes it easier for us, because we can perform a normal http POST using curl, and since the result we get back is HTML, we can use it as-is.
The result from W3C does state which lines in our document are erroneous, so we can add a very simple regexp replacement to make these statements into actual (txmt://) links.
The command to POST the current document to W3C’s validator and show the result, with line/column mentions made into links, is simply:
curl -F uploaded_file=@-\;type=text/html 2>/dev/null \
http://validator.w3.org/check \
| perl -pe 's|(Line (\d+) column (\d+))|<a href="txmt://open?line=$2&column=@{[$3 + 1]}">$1</a>|' \
| perl -pe 's|</title>|</title><base href="http://validator.w3.org/"/>|'
The second perl regexp replacement adds a <base> tag to make images and links in the result (from W3C) work when the URL is relative.
Interactive output
Besides HTML and CSS, the WebKit also has JavaScript support, which allow us to support various forms of interaction. For example the Subversion Log command allows you to show and hide files involved in each log message by linking to a JavaScript function which change the display property of the element which contain the files.
Running shell commands
In addition to the normal DOM there is a TextMate object with a system method which mimics the one available to Dashboard widgets.
This allows us to run shell commands from the HTML output, and if there’s something TextMate tries to prove, it is that shell access allow us to do anything :)
So for example the ri command (the Ruby doc lookup command) can be used to lookup current word (or selection) in the documentation like this (yes, it can already output as HTML):
ri -Tf html "${TM_SELECTED_TEXT:-$TM_CURRENT_WORD}"
One problem with this though, if we lookup length we get:
More than one method matched your request. You can refine
your search by asking for information on one of:
Array#length, Hash#length, MatchData#length, Queue#length,
Set#length, String#length, Struct#length, SyncEnumerator#length,
Tempfile#length
We can call ri again e.g. with String#length, but it would be nice if we could just click the one we wanted, and indeed that is possible.
1 ri -Tf html "${TM_SELECTED_TEXT:-$TM_CURRENT_WORD}"|{
2 read MSG
3 if grep -q <<<$MSG "More than one method matched"; then
4 cat <<-'EOF'
5 <script>function ri (arg) {
6 var cmd = "ri -T '" + arg + "'";
7 var res = TextMate.system(cmd, null).outputString;
8 document.getElementById("result").innerText = res;
9 window.location.hash = "result";
10 }
11 </script><h1>Multiple matches</h1><ul>
12 EOF
13 read MSG; read MSG
14 perl -pe $'s%(.+?)(, |$)%<li><a onClick=\'ri("$1")\'>$1</a></li>%g'
15 echo '</ul><hr><pre id="result"></pre>'
16 else
17 echo "$MSG"; cat
18 fi
19 }
The script is relatively simple (when you’ve spent a year writing shell scripts), but let me annotate it nonetheless.
- line 1
- First we simply run
riwith proper arguments. We need multiple commands to parse the result, so instead of piping it into a single command, we open a command block (using{) which means all commands in that block will be able to read the output fromri. - line 2-3
readis a command that reads a single line from stdin and stores that in the variable (given as argument). After having read one line from stdin, we usegrepto test ifrigave a More than one method matched result.- line 4
- We have determined that we got multiple candidates, so we start by outputting the JavaScript function that is to be used for our links. We output it using
catwith a heredoc. Quoting the heredoc token (EOF) means that variables should not be interpolated in the data, and prefixing it with a dash means that the end-token can be indented. - line 6-9
- This is the actual JS function which perform the magic. We start by composing the shell command string we want to execute, then execute it synchronously (by giving
nullas handler), for details of how to use the handler for asynchronous output, or how to feed the shell command with input, you can check Apple’s Dashboard documentation
After having read the result from the command, we setinnerHTMLof our output<pre>tag to it, and finally let the window scroll down to it by settingwindow.location.hash. - line 11-12
- Output some HTML to signal that there were multiple candidates and close the heredoc.
- line 13-14
- First skip the two empty lines which
rioutputs (by doing two reads) then have perl convert the list of candidates to actual HTML links which call our JS function on click.
I use a dollar quoted string ($'…') as the argument to perl, since I need to use both forms of quotes inside the string, which single quoted strings doesn’t allow, and double quoted strings interpolate variables (which I don’t want).
I also use%as regexp delimiter in the familiar perls/regexp/replacement/expression, this is just so that/can be used in the replacement w/o needing to be escaped. - line 17
- This line is executed in case
rididn’t return multiple candidates. First we output the first line we had to read (in order to perform the test) and then we callcat, which works like a pass-through operator (i.e. reads the rest of the output fromri, and writes that to stdout).
So there you have it, and this is how it looks:
Remembering state
Since some of the interactive commands may be toggling display attributes, it would be nice to have a way to store and retrieve the state of these.
For example the Run command in the Ruby bundle allows you to toggle whether script output should be wrapped or not. To store and retrieve this value, we make use of the defaults system in OS X.
The defaults system can be accessed from shell using the defaults shell command. For our use, the first argument should be read or write, the second argument is the domain we want to read/write from/to. This should be one of those reverse DNS names, i.e. if you own the domain fish.com, and you have made a command named swim, the domain you should use for attributes related to this command, should be com.fish.swim. If we want to read a value, the third and final argument should be the name we use for that value, for example we could do:
defaults read com.fish.swim backgroundColor
This will return the value for the backgroundColor attribute. Be aware that if there’s no value stored, it will output an error to stderr, and write nothing to stdout. So it’s probably best to do:
defaults read com.fish.swim backgroundColor 2>/dev/null
Which redirects stderr to /dev/null, and thus we can treat the empty string as if no value was set.
To write a value to the defaults, we also give the attribute as the third argument, optionally give the type of the value, and last the actual value. So e.g. to store (as a string) that the background color should be blue, we can do:
defaults write com.fish.swim backgroundColor -string blue
If you do not provide a type, it will try to parse the value as a property list, which is probably only a problem if the string contains a ( or {.
So from JavaScript, to store a value, we’d use a line like this:
TextMate.system("defaults write «domain» «attribute» «value»"), null);